spafe.features.rplp#
Description : (Rasta) Perceptual linear prediction coefficents (RPLPs/PLPs) extraction algorithm implementation.
Copyright (c) 2019-2024 Ayoub Malek. This source code is licensed under the terms of the BSD 3-Clause License. For a copy, see <https://github.com/SuperKogito/spafe/blob/master/LICENSE>.
- spafe.features.rplp.plp(sig: ndarray, fs: int = 16000, order: int = 13, pre_emph: bool = False, pre_emph_coeff: float = 0.97, window: Optional[SlidingWindow] = None, nfilts: int = 24, nfft: int = 512, low_freq: float = 0, high_freq: Optional[float] = None, scale: typing_extensions.Literal[ascendant, descendant, constant] = 'constant', lifter: Optional[int] = None, normalize: Optional[typing_extensions.Literal[mvn, ms, vn, mn]] = None, fbanks: Optional[ndarray] = None, conversion_approach: typing_extensions.Literal[Wang, Tjomov, Schroeder, Terhardt, Zwicker, Traunmueller] = 'Wang') ndarray[source]#
Compute Perceptual linear prediction coefficents according to [Hermansky] and [Ajibola].
- Parameters
sig (numpy.ndarray) – a mono audio signal (Nx1) from which to compute features.
fs (int) – the sampling frequency of the signal we are working with. (Default is 16000).
order (int) – number of cepstra to return. (Default is 13).
pre_emph (bool) – apply pre-emphasis if 1. (Default is 1).
pre_emph_coeff (float) – pre-emphasis filter coefficient. (Default is 0.97).
window (SlidingWindow) – sliding window object. (Default is None).
nfilts (int) – the number of filters in the filter bank. (Default is 40).
nfft (int) – number of FFT points. (Default is 512).
low_freq (float) – lowest band edge of mel filters (Hz). (Default is 0).
high_freq (float) – highest band edge of mel filters (Hz). (Default is samplerate/2).
scale (str) – monotonicity behavior of the filter banks. (Default is “constant”).
lifter (int) – apply liftering if specified. (Default is None).
normalize (str) – apply normalization if approach specified. (Default is None).
fbanks (numpy.ndarray) – filter bank matrix. (Default is None).
conversion_approach (str) – bark scale conversion approach. (Default is “Wang”).
- Returns
2d array of PLP features (num_frames x order)
- Return type
Tip
normalize: can take the following options [“mvn”, “ms”, “vn”, “mn”].conversion_approach: can take the following options [“Tjomov”,”Schroeder”, “Terhardt”, “Zwicker”, “Traunmueller”, “Wang”]. Note that the use of different options than the ddefault can lead to unexpected behavior/issues.
Note

Architecture of perceptual linear prediction coefficients extraction algorithm.#
Examples
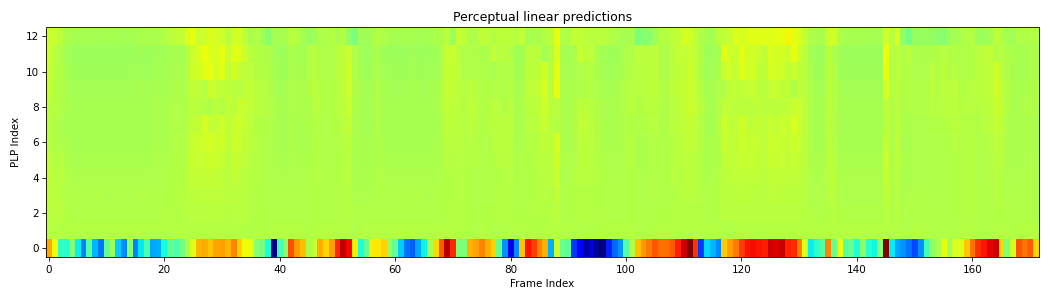
from scipy.io.wavfile import read from spafe.features.rplp import plp from spafe.utils.preprocessing import SlidingWindow from spafe.utils.vis import show_features # read audio fpath = "../../../tests/data/test.wav" fs, sig = read(fpath) # compute plps plps = plp(sig, fs=fs, pre_emph=0, pre_emph_coeff=0.97, window=SlidingWindow(0.03, 0.015, "hamming"), nfilts=128, nfft=1024, low_freq=0, high_freq=fs/2, lifter=0.9, normalize="mvn") # visualize features show_features(plps, "Perceptual linear predictions", "PLP Index", "Frame Index")
- spafe.features.rplp.rplp(sig: ndarray, fs: int = 16000, order: int = 13, pre_emph: bool = False, pre_emph_coeff: float = 0.97, window: Optional[SlidingWindow] = None, nfilts: int = 24, nfft: int = 512, low_freq: float = 0, high_freq: Optional[float] = None, scale: typing_extensions.Literal[ascendant, descendant, constant] = 'constant', lifter: Optional[int] = None, normalize: Optional[typing_extensions.Literal[mvn, ms, vn, mn]] = None, fbanks: Optional[ndarray] = None, conversion_approach: typing_extensions.Literal[Wang, Tjomov, Schroeder, Terhardt, Zwicker, Traunmueller] = 'Wang') ndarray[source]#
Compute rasta Perceptual linear prediction coefficents according to [Hermansky] and [Ajibola].
- Parameters
sig (numpy.ndarray) – a mono audio signal (Nx1) from which to compute features.
fs (int) – the sampling frequency of the signal we are working with. (Default is 16000).
order (int) – number of cepstra to return. (Default is 13).
pre_emph (bool) – apply pre-emphasis if 1. (Default is True).
pre_emph_coeff (float) – pre-emphasis filter coefficient. (Default is 0.97).
window (SlidingWindow) – sliding window object. (Default is None).
nfilts (int) – the number of filters in the filter bank. (Default is 40).
nfft (int) – number of FFT points. (Default is 512).
low_freq (float) – lowest band edge of mel filters (Hz). (Default is 0).
high_freq (float) – highest band edge of mel filters (Hz). (Default is samplerate/2).
scale (str) – monotonicity behavior of the filter banks. (Default is “constant”).
lifter (int) – apply liftering if specified. (Default is None).
normalize (str) – apply normalization if approach specified. (Default is None).
fbanks (numpy.ndarray) – filter bank matrix. (Default is None).
conversion_approach (str) – bark scale conversion approach. (Default is “Wang”).
- Returns
2d array of rasta PLP features (num_frames x order)
- Return type
Tip
normalize: can take the following options [“mvn”, “ms”, “vn”, “mn”].conversion_approach: can take the following options [“Tjomov”,”Schroeder”, “Terhardt”, “Zwicker”, “Traunmueller”, “Wang”]. Note that the use of different options than the ddefault can lead to unexpected behavior/issues.
Note

Architecture of rasta perceptual linear prediction coefficients extraction algorithm.#
Examples
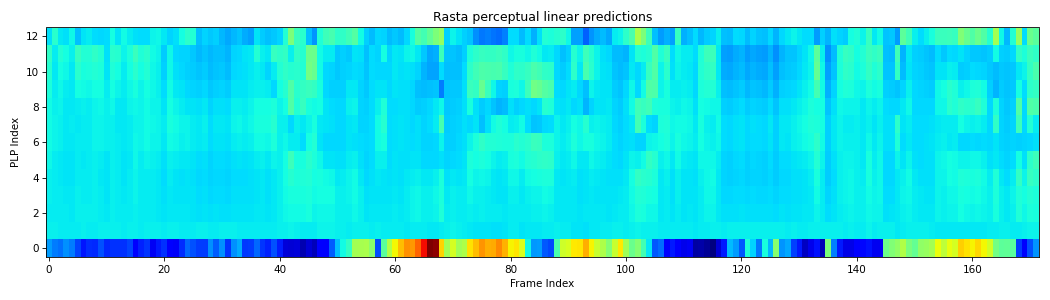
from scipy.io.wavfile import read from spafe.features.rplp import rplp from spafe.utils.preprocessing import SlidingWindow from spafe.utils.vis import show_features # read audio fpath = "../../../tests/data/test.wav" fs, sig = read(fpath) # compute rplps rplps = rplp(sig, fs=fs, pre_emph=0, pre_emph_coeff=0.97, window=SlidingWindow(0.03, 0.015, "hamming"), nfilts=128, nfft=1024, low_freq=0, high_freq=fs/2, lifter=0.9, normalize="mvn") # visualize features show_features(rplps, "Rasta perceptual linear predictions", "PLP Index", "Frame Index")
References