Naive voice activity detection using short time energy#
An important part of speech/speaker recognition tasks is distinction of voiced segments from silent ones. This helps -for example- align phonemes with their associated voiced segments and avoid any extra information related to silence/ noise that would degrade the system's accuracy. This problem is known as Voice Activity Detection (VAD). This blog aims to introduce voice activity detection and present simple short time energy based VAD implementation.
What is voice activity detection ?#
Voice activity detection is a speech/signal processing technique in which the presence or absence of human speech is detected. VAD is often used in speech coding and speech recognition but it also helps optimize and speed audio dependent approach like speaker recognition.
Why do we do need voice activity detection?#
As mentioned before VAD is very useful in many audio processing related tasks. A couple of these uses are highlighted in the following list:
In speech recognition, VAD helps improve the quality by masking the effect of silent frames and noise.
In Speech enhancement, VAD can be used to collect silent frames to get a good noise estimation for example.
In Speaker recognition, VAD allows for better quality detection since the recognition will be based only on "pure" speech frames.
In many other applications, VAD is used to accelerate the processing and avoid extra runs for silent frames.
How to implement it?#
The basic assumption behind short time energy based VAD is that voiced frames has more energy than silent. Therefore, we can frame the signal, compute the short time energy aka the energy pro frame and according to a predefined threshold we can decide where the frame is voiced or silent [1]. These steps can be summarized in the following:
Frame signal (refer to Signal_framing).
Assuming a signal \(S\), this can be formulated as follows: \(S = \sum_{n=0}^{N_s-1} x[n] = \sum_{i=0}^{\#F-1} f[i]\) where:
\(S\): Discrete signal.
\(x[n]\): Signal sample in time domain.
\(N_s\) : Signal length in samples.
\(f[i]\): Signal frame.
\(\#F\) : Number of frames.
Compute the energy per frame aka short time energy.
The short time energy can be assumed to be the total energy of each. The energy pro frame is \(E_f = \sum_{n=0}^{N_f - 1} |x[n]|^2\), and consequently the normalized short time energy value, is \(\overline{E}_f = \frac{1}{N_f - 1}.\sum_{n=0}^{N_f - 1} |x[n]|^2\). Based on the Parseval's theorem , we can use the discrete Fourrier transform to compute the energy since: \(\sum_{n=0}^{N_f - 1} |x[n]|^2 = \frac{1}{N_f - 1}.\sum_{n=0}^{N_f - 1} |X[n]|^2\). To summarize: \(\overline{E}_f = \frac{1}{(N_f - 1)^2}.\sum_{n=0}^{N_f - 1} |X[n]|^2\)
with:
\(E_f[n]\): Frame total energy.
\(\overline{E}_f[n]\): Normalized frame total energy.
\(x[n]\): Signal sample in the time domain.
\(X[n]\): Signal sample in the frequency domain.
\(N_f\) : Frame length in samples.
\(F[i]\): Signal frame.
\(\#F\) : Number of frames.
A standard practice is to convert the computed energy to Decibels using a suitably chosen \(E_0\) (Energy value characterizing the silence to speech energy ratio):
\begin{equation} \overline{E}_{f_{dB}} = 10 ⋅ \log_{10}(\frac{\overline{E}_f}{E_0}) \end{equation}Construct VAD array using threshold comparison the energy.
By comparing the short time energy values to a predefined energy threshold, we compute the VAD as follows:
\begin{equation} VAD[n]=\left\{\begin{array}{ll} {0,} & {\overline{E}_f[n] \leq threshold \implies Silence} \\ {1,} & {\overline{E}_f[n] > threshold \implies Speech} \end{array}\right. \end{equation}with:
\(VAD[n]\): The Voice Activity Detection array.
\(\overline{E}_f[n]\): Normalized frame total energy.
Compute the voiced Signal.
\begin{equation} \widetilde{S}[n]= S[n] . VAD[n] \end{equation}with:
\(\widetilde{S}[n]\): Silence filtered signal.
\(VAD[n]\): The Voice Activity Detection array.
\(S[n]\) : The original signal.
The code for the previous steps is the following (I added a visualization function to help visualize the concept):
1import scipy
2import numpy as np
3import scipy.signal
4import scipy.io.wavfile
5import matplotlib.pyplot as plt
6
7
8def stride_trick(a, stride_length, stride_step):
9 """
10 apply framing using the stride trick from numpy.
11
12 Args:
13 a (array) : signal array.
14 stride_length (int) : length of the stride.
15 stride_step (int) : stride step.
16
17 Returns:
18 blocked/framed array.
19 """
20 nrows = ((a.size - stride_length) // stride_step) + 1
21 n = a.strides[0]
22 return np.lib.stride_tricks.as_strided(a,
23 shape=(nrows, stride_length),
24 strides=(stride_step*n, n))
25
26
27def framing(sig, fs=16000, win_len=0.025, win_hop=0.01):
28 """
29 transform a signal into a series of overlapping frames (=Frame blocking).
30
31 Args:
32 sig (array) : a mono audio signal (Nx1) from which to compute features.
33 fs (int) : the sampling frequency of the signal we are working with.
34 Default is 16000.
35 win_len (float) : window length in sec.
36 Default is 0.025.
37 win_hop (float) : step between successive windows in sec.
38 Default is 0.01.
39
40 Returns:
41 array of frames.
42 frame length.
43
44 Notes:
45 ------
46 Uses the stride trick to accelerate the processing.
47 """
48 # run checks and assertions
49 if win_len < win_hop: print("ParameterError: win_len must be larger than win_hop.")
50
51 # compute frame length and frame step (convert from seconds to samples)
52 frame_length = win_len * fs
53 frame_step = win_hop * fs
54 signal_length = len(sig)
55 frames_overlap = frame_length - frame_step
56
57 # compute number of frames and left sample in order to pad if needed to make
58 # sure all frames have equal number of samples without truncating any samples
59 # from the original signal
60 rest_samples = np.abs(signal_length - frames_overlap) % np.abs(frame_length - frames_overlap)
61 pad_signal = np.append(sig, np.array([0] * int(frame_step - rest_samples) * int(rest_samples != 0.)))
62
63 # apply stride trick
64 frames = stride_trick(pad_signal, int(frame_length), int(frame_step))
65 return frames, frame_length
66
67
68def _calculate_normalized_short_time_energy(frames):
69 return np.sum(np.abs(np.fft.rfft(a=frames, n=len(frames)))**2, axis=-1) / len(frames)**2
70
71
72def naive_frame_energy_vad(sig, fs, threshold=-20, win_len=0.25, win_hop=0.25, E0=1e7):
73 # framing
74 frames, frames_len = framing(sig=sig, fs=fs, win_len=win_len, win_hop=win_hop)
75
76 # compute short time energies to get voiced frames
77 energy = _calculate_normalized_short_time_energy(frames)
78 log_energy = 10 * np.log10(energy / E0)
79
80 # normalize energy to 0 dB then filter and format
81 energy = scipy.signal.medfilt(log_energy, 5)
82 energy = np.repeat(energy, frames_len)
83
84 # compute vad and get speech frames
85 vad = np.array(energy > threshold, dtype=sig.dtype)
86 vframes = np.array(frames.flatten()[np.where(vad==1)], dtype=sig.dtype)
87 return energy, vad, np.array(vframes, dtype=np.float64)
88
89
90def multi_plots(data, titles, fs, plot_rows, step=1, colors=["b", "r", "m", "g", "b", "y"]):
91 # first fig
92 plt.subplots(plot_rows, 1, figsize=(20, 10))
93 plt.subplots_adjust(left=0.125, right=0.9, bottom=0.1, top=0.99, wspace=0.4, hspace=0.99)
94
95 for i in range(plot_rows):
96 plt.subplot(plot_rows, 1, i+1)
97 y = data[i]
98 plt.plot([i/fs for i in range(0, len(y), step)], y, colors[i])
99 plt.gca().set_title(titles[i])
100 plt.show()
101
102 # second fig
103 sig, vad = data[0], data[-2]
104 # plot VAD and orginal signal
105 plt.subplots(1, 1, figsize=(20, 10))
106 plt.plot([i/fs for i in range(len(sig))], sig, label="Signal")
107 plt.plot([i/fs for i in range(len(vad))], max(sig)*vad, label="VAD")
108 plt.legend(loc='best')
109 plt.show()
110
111
112if __name__ == "__main__":
113 # init vars
114 fname = "OSR_us_000_0060_8k.wav"
115 fs, sig = scipy.io.wavfile.read(fname)
116
117 #########################
118 # naive_frame_energy_vad
119 #########################
120 # get voiced frames
121 energy, vad, voiced = naive_frame_energy_vad(sig, fs, threshold=-35,
122 win_len=0.025, win_hop=0.025)
123
124 # plot results
125 multi_plots(data=[sig, energy, vad, voiced],
126 titles=["Input signal (voiced + silence)", "Short time energy",
127 "Voice activity detection", "Output signal (voiced only)"],
128 fs=fs, plot_rows=4, step=1)
129
130 # save voiced signal
131 scipy.io.wavfile.write("naive_frame_energy_vad_no_silence_"+ fname,
132 fs, np.array(voiced, dtype=sig.dtype))
The resulting plots clearly show a good performance of this simple and fast VAD.
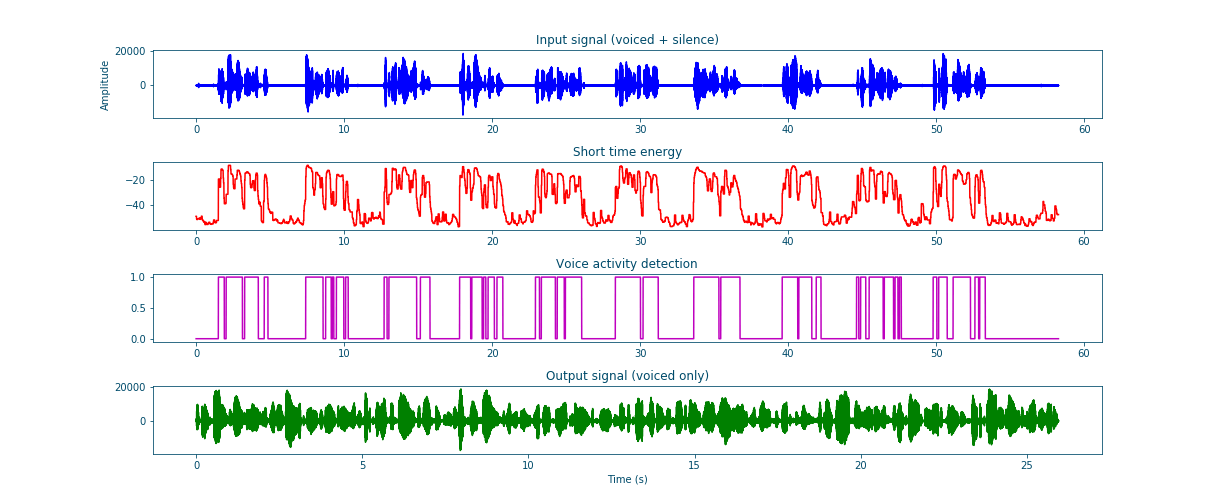
Figure 17: Summary plots of voice activity detection#
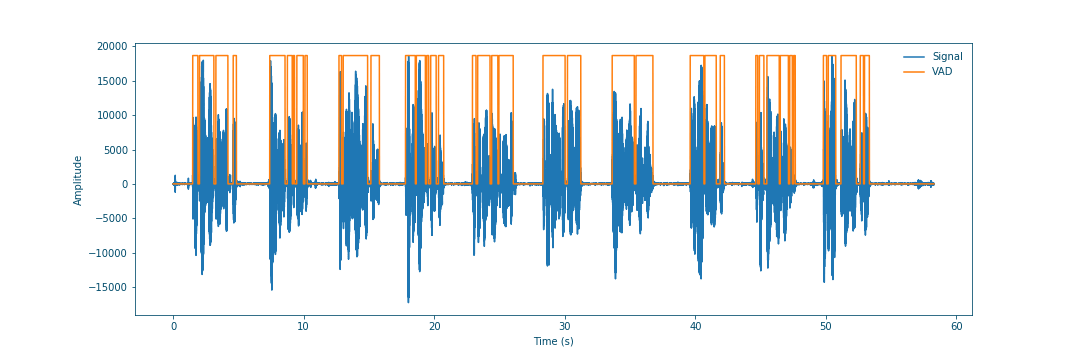
Figure 18: Voice activity detection and original signal#
I already tested the VAD using the following sample that can be downloaded from Open Speech Repository. The difference between the input and output shows that the VAD is functional.
| Input signal (voiced and silent frames) | |
| Output signal (voiced only frames) |
Conclusion#
This blog gave a quick overview to voice activity detection and its use in practical speech/ signal processing applications. It also introduced a naive simple way to distinguish silence from speech using short time energy. This type of VAD, though it is fast & simple, it lacks accuracy in some cases as it is dependent on the manual choice of threshold and \(E_0\) (Energy value characterizing the silence to speech energy ratio). Therefore, it is advised to equalize the input audio before the processing. Alternative approaches to VAD uses extra features such as MFCCs and are based on machine learning algorithms.