Voice based gender recognition using Gaussian mixture models#

Figure 4: Voice based gender recognition overview
This blog presents an approach to recognizing a Speaker's gender by voice using the Mel-frequency cepstrum coefficients (MFCC) and Gaussian mixture models (GMM). The post provides an explanation of the following GitHub-project Voice-based-gender-recognition.
| Watch | Star | Fork | Download | Follow @SuperKogito |
|---|
The aforementioned implementation, uses The Free ST American English Corpus data-set (SLR45), which is a free American English corpus by Surfingtech, containing utterances from 10 speakers (5 females and 5 males).
Keywords: Gender recognition, Mel-frequency cepstrum coefficients, The Free ST American English Corpus data-set, Gaussian mixture models
Introduction#
The idea here is to recognize the gender of the speaker based on pre-generated Gaussian mixture models (GMM). Once the data is properly formatted, we train our Gaussian mixture models for each gender by gathering Mel-frequency cepstrum coefficients (MFCC) from their associated training wave files. Now that we have generated the models, we identify the speakers genders by extracting their MFCCs from the testing wave files and scoring them against the models. These scores represent the likelihood that user MFCCs belong to one of the two models. The gender models with the highest score represents the probable gender of the speaker. In the following table, we summarize the previous main steps, as for a detailed modeling of the processing steps, you can refer to the Workflow graph in Figure_5.
|
|
|
|
Workflow graph#
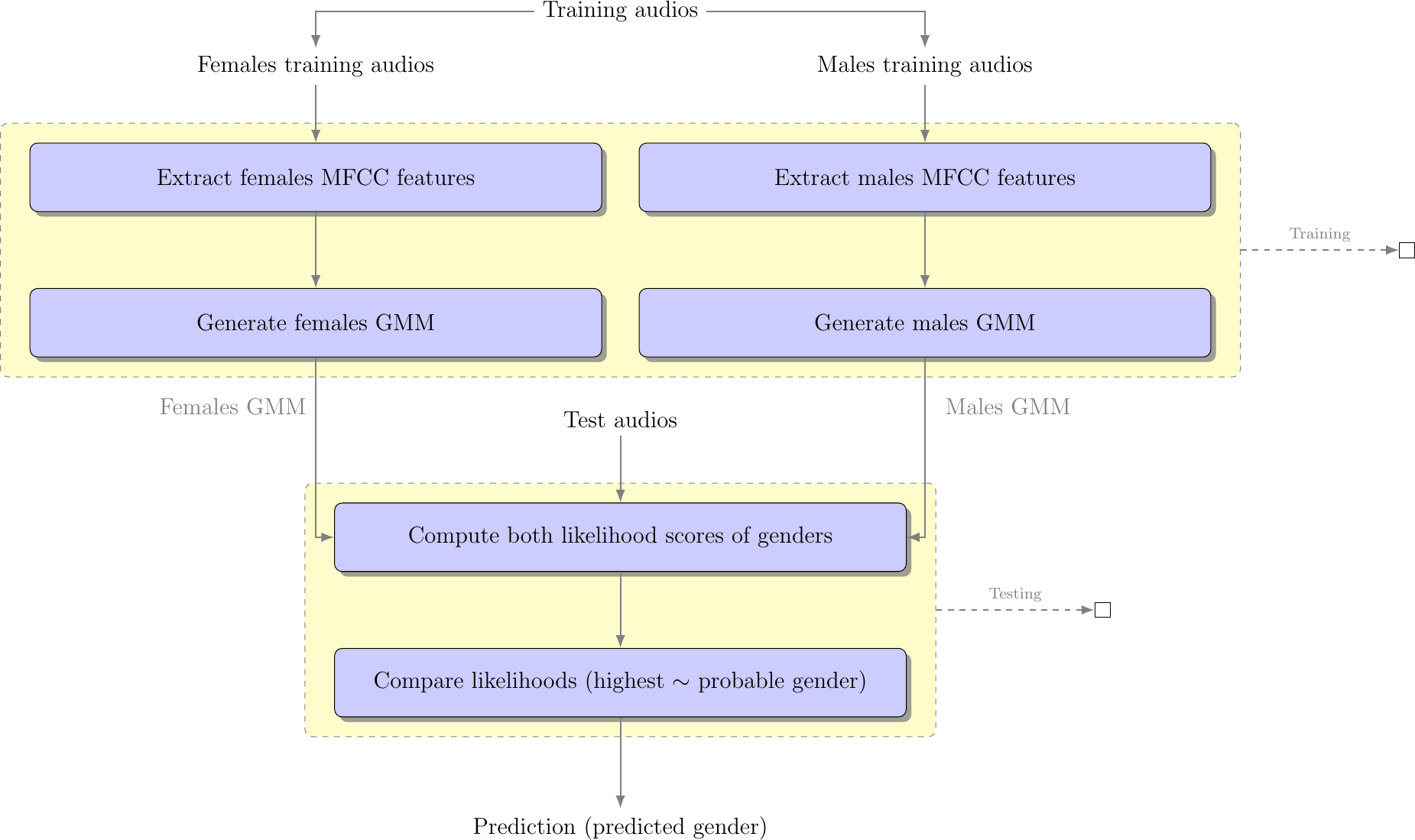
Figure 5: Voice based gender recognition
Data formatting#
Once you download your data-set, you will need to split it into two different sets:
Training set: This set will be used to train the gender models.
Testing set: This one will serve for testing the accuracy of the gender recognition.
I usually use 2/3 of the the data for the training and 1/3 for the testing, but you can adjust that to your needs/ wishes. The code provides an option for running the whole cycle using "Run.py" or you can go step by step and for the data management just run the following in your terminal:
$ python3 Code/DataManager.py
Voice features extraction#
The Mel-Frequency Cepstrum Coefficients (MFCC) are used here, since they deliver the best results in speaker verification [1]. MFCCs are commonly derived as follows:
Take the Fourier transform of (a windowed excerpt of) a signal.
Map the powers of the spectrum obtained above onto the mel scale, using triangular overlapping windows.
Take the logs of the powers at each of the mel frequencies.
Take the discrete cosine transform of the list of mel log powers, as if it were a signal.
The MFCCs are the amplitudes of the resulting spectrum.
To extract MFCC features I usually use the python_speech_features library, it is simple to use and well documented:
1 import numpy as np
2 from sklearn import preprocessing
3 from scipy.io.wavfile import read
4 from python_speech_features import mfcc
5 from python_speech_features import delta
6
7 def extract_features(audio_path):
8 """
9 Extract MFCCs, their deltas and double deltas from an audio, performs CMS.
10
11 Args:
12 audio_path (str) : path to wave file without silent moments.
13 Returns:
14 (array) : Extracted features matrix.
15 """
16 rate, audio = read(audio_path)
17 mfcc_feature = mfcc(audio, rate, winlen = 0.05, winstep = 0.01, numcep = 5, nfilt = 30,
18 nfft = 512, appendEnergy = True)
19
20 mfcc_feature = preprocessing.scale(mfcc_feature)
21 deltas = delta(mfcc_feature, 2)
22 double_deltas = delta(deltas, 2)
23 combined = np.hstack((mfcc_feature, deltas, double_deltas))
24 return combined
Gaussian Mixture Models#
According to D. Reynolds in Gaussian_Mixture_Models:
<< A Gaussian Mixture Model (GMM) is a parametric probability density function represented as a weighted sum of Gaussian component densities. GMMs are commonly used as a parametric model of the probability distribution of continuous measurements or features in a biometric system, such as vocal-tract related spectral features in a speaker recognition system. GMM parameters are estimated from training data using the iterative Expectation-Maximization (EM) algorithm or Maximum A Posteriori(MAP) estimation from a well-trained prior model. >>
In a some way, you can consider a Gaussian mixture model as a probabilistic clustering representing a certain data distribution as a sum of Gaussian density functions (check Figure_6) [2][3]. These densities forming a GMM are also called the components of the GMM. The likelihood of data points (feature vectors) for a model is given by following equation [1] \(\begin{equation} P(X | \lambda)=\sum_{k=1}^{K} w_{k} P_{k}\left(X | \mu_{k}, \Sigma_{k}\right) \end{equation}\), where \(\begin{equation} P_{k}\left(X | \mu_{k}, \Sigma_{k}\right)=\frac{1}{\sqrt{2 \pi\left|\Sigma_{k}\right|}} e^{\frac{1}{2}\left(X-\mu_{k}\right)^{T} \Sigma^{-1}\left(X-\mu_{k}\right)} \end{equation}\) is the Gaussian distribution, with:
\(\lambda\) represents the training data.
\(\mu\) is the mean.
\(\Sigma\) is co-variance matrices.
\(w_{k}\) represent the weights.
\(k\) refers the index of the GMM components.
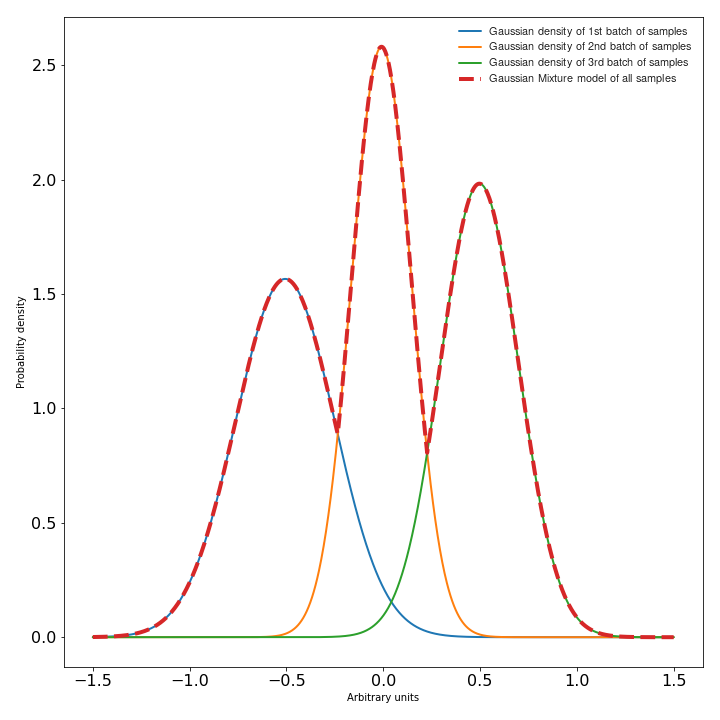
Figure 6: Simplified Gaussian mixture model visualization#
To train a Gaussian mixture models based on some collected features, you can use scikit-learn-library specifically the scikit-learn-gmm:
1import os
2import pickle
3from sklearn.mixture import GMM
4
5
6def save_gmm(gmm, name):
7 """ Save Gaussian mixture model using pickle.
8 Args:
9 gmm : Gaussian mixture model.
10 name (str) : File name.
11 """
12 filename = name + ".gmm"
13 with open(filename, 'wb') as gmm_file:
14 pickle.dump(gmm, gmm_file)
15 print ("%5s %10s" % ("SAVING", filename,))
16
17...
18# get gender_voice_features using FeaturesExtraction
19# generate gaussian mixture models
20gender_gmm = GMM(n_components = 16, n_iter = 200, covariance_type = 'diag', n_init = 3)
21# fit features to models
22gender_gmm.fit(gender_voice_features)
23# save gmm
24save_gmm(gender_gmm, "gender")
Gender identification#
The identification is done over three steps: first you retrieve the voice features, then you compute their likelihood of belonging to a certain gender and finally your compare both scores and make a decision on the probable gender. The computation of the scores is done as follows [4] [5].
Given a speech Y and speaker S, the gender recognition test can be restated into a basic hypothesis test between \(H_{f}\) and \(H_{m}\), where:
\(H_{f}\) : Y is a FEMALE
\(H_{f}\) : Y is a MALE
\begin{eqnarray} \frac{p\left(Y | H_{f}\right)}{p\left(Y | H_{m}\right)} = \left\{\begin{array}{ll}{ \geq 1} & {\text { accept } H_{f}} \\ {< 1} & {\text { reject } H_{m}}\end{array} \right. \end{eqnarray}where \(\begin{eqnarray} p\left(Y | H_{i}\right) \end{eqnarray}\), is the probability density function for the hypothesis \(H_{i}\) evaluated for the observed speech segment Y, also called the likelihood of the hypothesis \(H_{i}\) given the speech segment Y [4].
1import pickle
2import numpy as np
3from FeaturesExtractor import FeaturesExtractor
4
5def identify_gender(vector):
6 # female hypothesis scoring
7 is_female_scores = np.array(self.females_gmm.score(vector))
8 is_female_log_likelihood = is_female_scores.sum()
9
10 # male hypothesis scoring
11 is_male_scores = np.array(self.males_gmm.score(vector))
12 is_male_log_likelihood = is_male_scores.sum()
13
14 # print scores
15 print("%10s %5s %1s" % ("+ FEMALE SCORE",":", str(round(is_female_log_likelihood, 3))))
16 print("%10s %7s %1s" % ("+ MALE SCORE", ":", str(round(is_male_log_likelihood,3))))
17
18 # find the winner aka the probable gender of the speaker
19 if is_male_log_likelihood > is_female_log_likelihood: winner = "male"
20 else : winner = "female"
21 return winner
22
23
24# init instances and load models
25features_extractor = FeaturesExtractor()
26females_gmm = pickle.load(open(females_model_path, 'rb'))
27males_gmm = pickle.load(open(males_model_path, 'rb'))
28
29# read the test directory and get the list of test audio files
30file = "speaker-test-file.wav"
31vector = features_extractor.extract_features(file)
32winner = identify_gender(vector)
33expected_gender = file.split("/")[1][:-1]
34
35print("%10s %6s %1s" % ("+ EXPECTATION",":", expected_gender))
36print("%10s %3s %1s" % ("+ IDENTIFICATION", ":", winner))
Code & scripts#
The full code for this approach to voice based gender identification can be found on GitHub under Voice-based-gender-recognition.
Obviously the code provided on GitHub is more structured and advanced than what provided here since it is used to process multiple files,and to compute the accuracy level
Results summary#
The results of the gender recognition tests can be summarized in the following table/ confusion matrix:
Female expected |
Male expected |
|
Female guessed |
563 |
28 |
Male guessed |
21 |
376 |
Using the previous results we can compute the following system characteristics:
Precision for female recognition = 563 / (563 + 28) = 0.95
Precision for male recognition = 376 / (376 + 21) = 0.94
Accuracy = 939 / 988 = 0.95
Conclusions#
The system results in a 95% accuracy of gender detection, but this can be different for other data-sets.
The code can be further optimized using multi-threading, acceleration libs and multi-processing.
The accuracy can be further improved using GMM normalization aka a UBM-GMM system.